注:本文仅针对Cortex-M3/4 系列进行讲述。
在传统的ARM处理器架构中,常使用SWP指令来实现锁的读/写原子操作,但从ARM v6开始,读/写访问在独立的两条总线上进行,SWP指令已无法在此架构下保证读/写访问的原子操作,因此互斥访问指令应运而生。本文结合项目中运用的相关方法,总结Cortex-M芯片常用的互斥访问方法。
互斥访问方式1--LDREX/STREX指令
ARM支持的互斥指令对有LDREX/STREX、LDREXB/STREXB 及 LDREXH/STREXH(专有的寄存器加载/存储指令),其分别支持字/字节/半字访问,本节以LDREX/STREX为例.
语法格式
LDREX{cond} Rt, [Rn {, #offset}]
STREX{cond} Rd, Rt, [Rn {, #offset}]
其中
cond: 可选状态码-若指令包含此状态码,则只有当APSR寄存器中的状态位满足状态码条件时,指令才会执行
Rd: 目的寄存器-指令执行后的返回状态,0执行成功,1执行失败
Rt: 待加载/存储的寄存器
Rn: 寄存器地址
offset: 可选的地址偏移
基本要求
使用互斥访问指令时,需满足以下基本要求,以防不可预期的结果出现。
1. LDREX/STREX必须成对出现
2. LDREX/STREX的Rn寄存器地址必须一致,操作的寄存器长度必须一致
3. LDREX/STREX之间不得使用PC指针,操作的寄存器不使用SP指针
4. LDREX/STREX之间的指令要尽可能的简短,offset需4字节对齐,范围在0~1020之间(不同的厂商设置范围不同)
互斥写失败情况
在满足基本要求后,互斥写不一定成功,如互斥操作中途遇到以下情况:
1. 调用CLREX指令清除互斥状态
2. 发生上下午切换(如中断)
3. 之前未执行过LDREX
4. 总线反馈的互斥错误
使用方法
以nRF52源码中的 nrf_atomic_internal_orr() 函数为例,该函数实现了或运算的原子操作,其中p_ptr为初始值,value为或运算因子,p_new为运算后的值,函数返回原为子操作之前的p_ptr的值。
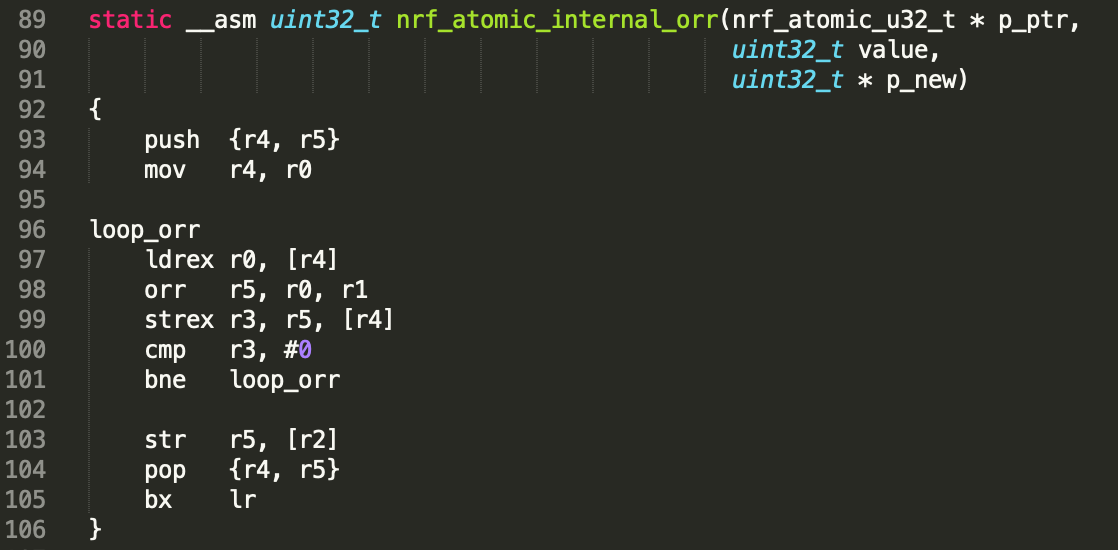
先简单描述上述各行代码:
89: r0/r1/r2分别存储的p_ptr/value/p_new的值
94:将p_ptr地址付给r4
97:将r4所指向的值赋给r0,r0获得了p_ptr此时的值
98:对r0存储的值进行或运算,运算值赋给r5
99:将r5的值存储给r4指向的地址,即更新p_ptr的值,同时将本条指令的执行结果赋给r3
100/101:判断返回值r3,若不为0,重试 97~99的操作
103/104/105:将运算值赋给r2指向的值,即得到新值
代码的关键在97行,需注意的是,当函数执行结束返回时,r0存储函数的返回值,因此此函数的返回值为原子操作之前的p_ptr值,而不是调用此函数时传入的p_ptr值(中途可能有变)
以实际场景为例,假若存在两个任务A和B,以及一个共享内存Mem,互斥变量Flag标记Mem是否正在被占用(0:空闲中,1:占用中),要如何实现呢?
情况1. A/B先后访问Mem,则
1. A首先调用 nrf_atomic_internal_orr() 函数(Flag=0),尝试原子操作,此时R0=0,执行结束后,由返回值R0可知,Flag成功由0->1,A占用Mem成功
2. 此时发生任务切换
3. B调用 nrf_atomic_internal_orr() 函数(Flag=1),尝试原子操作,此时R0=1,执行结束后,由返回值R0可知,Flag在置位之前已经是1,B占用Mem失败
注:因为只有A/B先后访问nrf_atomic_internal_orr()函数,因此各自只需要尝试一次原子操作即可成功。
情况2.A/B同时访问Mem,A在原子操作过程中被B抢占,则
1. A首先调用 nrf_atomic_internal_orr() 函数(Flag=0),尝试第一次原子操作,此时R0=0,此时发生任务切换
2. A被抢占,上下文切换退出
3. B调用 nrf_atomic_internal_orr() 函数(Flag=0),尝试第一次原子操作,此时R0=0,执行结束后,由返回值R0可知,Flag成功由0->1,B占用Mem成功
4. 此时发生任务切换
5. A继续执行第一次原子操作,因在LDREX/STREX之间已发生上下文切换,此次原子操作STREX返回 1,执行失败
6. A继续执行第二次原子操作,注意:此时R0重载,R0=1,执行结束后,由返回值R0可知,Flag在置位之前已经是1,A占用Mem失败
因此本例中,调用nrf_atomic_internal_orr() 执行原子操作后,通过判断函数返回值可知,本次互斥操作是否抢占资源成功。
互斥访问方式2--Bit-Band操作
在支持 “locked transfers”或仅有单个总线主机的内存系统中,使用位带操作也可实现信号量操作。要实现互斥访问某个资源,操作过程中需遵循以下几点:
1. 系统为每个需互斥访问的任务分配一个位带bit位,
2. 任务仅能对自己的bit位进行读-修改-写操作。
2. 不能以常规的写方式来直接修改位带区域值,否则可能丢失已锁定的位信息
具体操作过程直接上图:
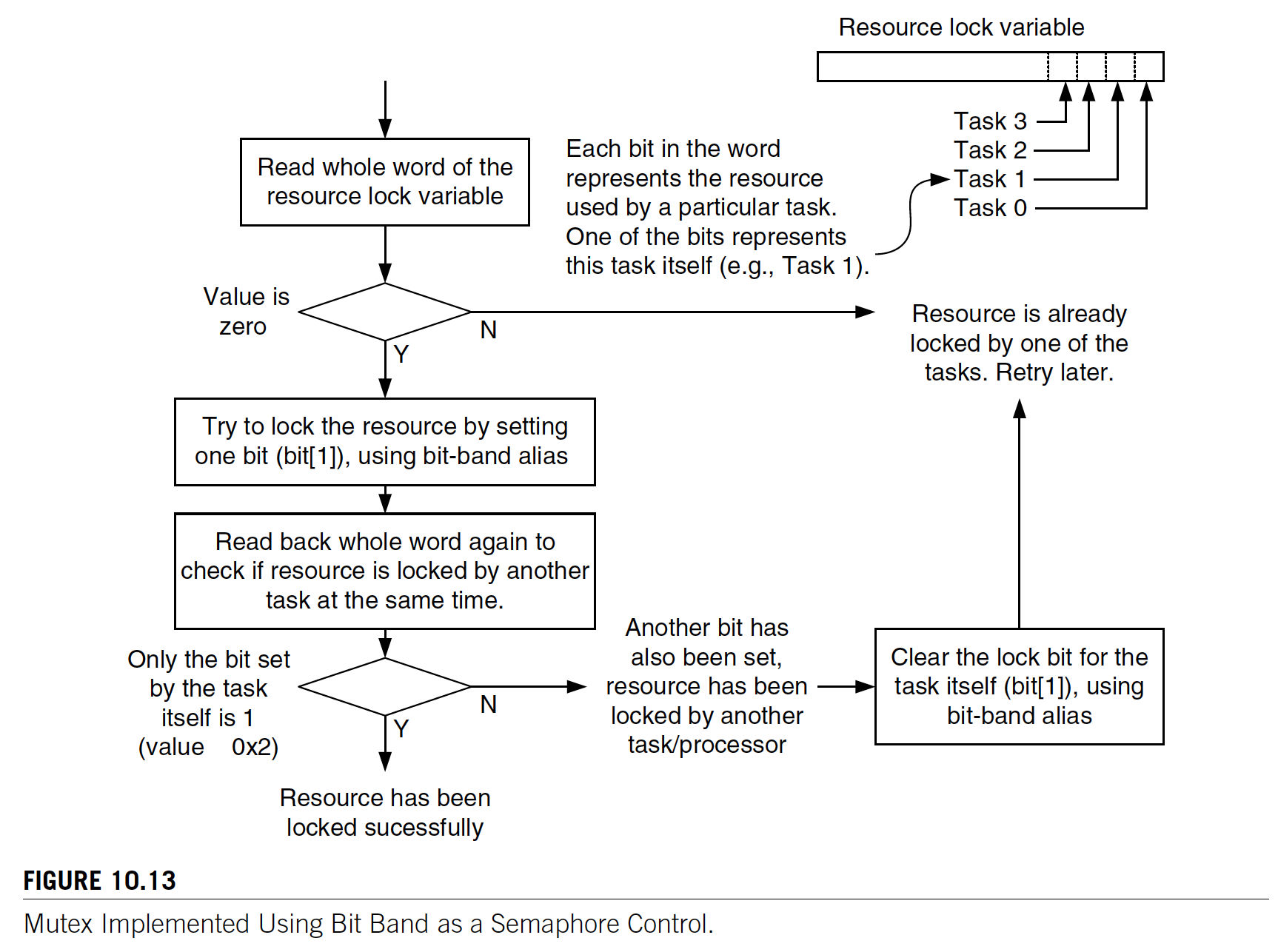
优点:可使用C代码直接实现上述互斥访问逻辑。
互斥访问方式3--关中断
最为简单粗暴的互斥访问方法,FreeRTOS的信号量获取/释放操作便采用此方式进入临界区。
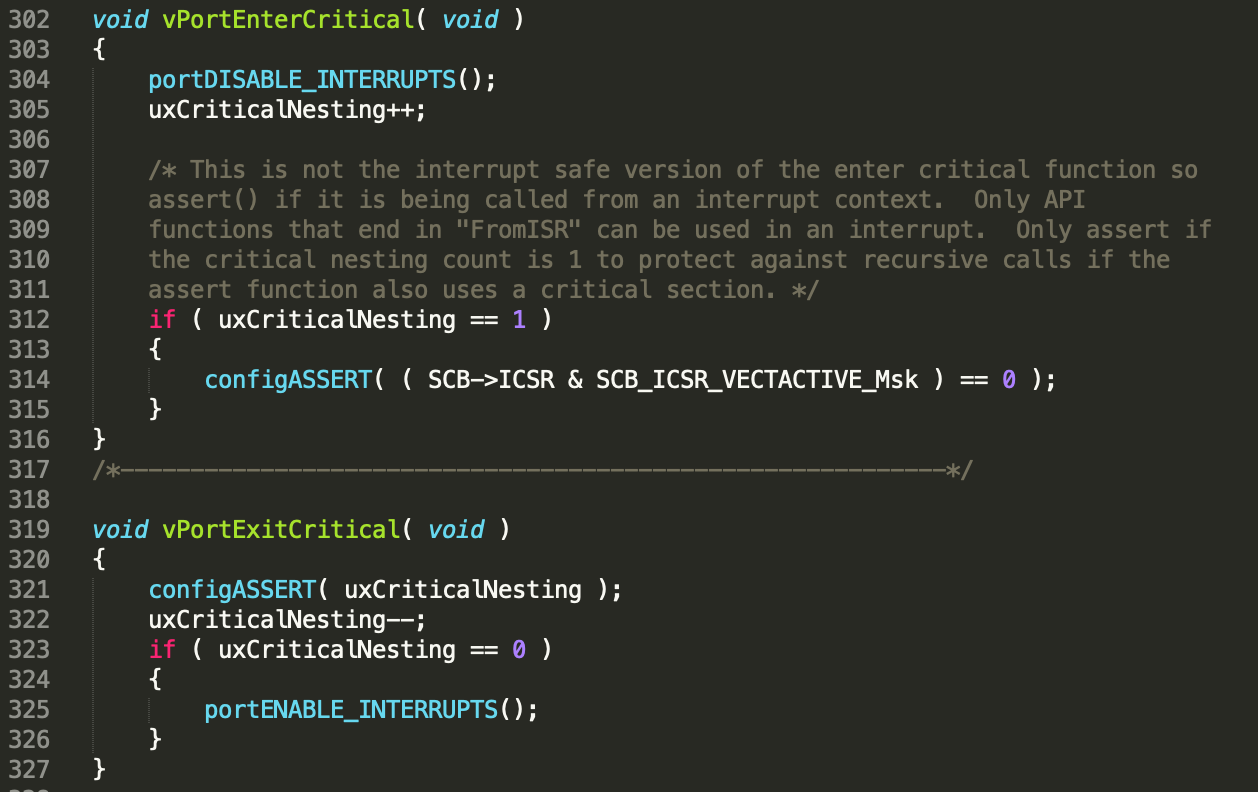
关中断实现起来虽然简单,但也需根据具体场景来选择关总中断还是外设中断,否则可能降低系统的实时性甚至造成数据丢失。
举例来说,在之前经历的一个项目中,有一款MCU既需要负责USB数据的收发,同时还得处理无线数据的转发,如在处理USB临界区数据时选择关总中断,则可能导致无线数据无法及时处理甚至导致丢包,在该场景下,若选择只关闭USB中断,则MCU依然能够在实现局部互斥操作的同时实时响应优先级更高的事件。
参考手册
TI 《Cortex-M3/M4F Instruction Set》
宋岩 《Cortex -M3 权威指南》
《The Definitive guild to the ARM Cortex-M3》Second Edition》
《The Definitive guild to the ARM Cortex-M3 and Cortex-M4 Processors》Third Edition